This is the third of a series of three posts I’ve done on DevOps recently. The first focused on the three ways explored in the Phoenix Project, and I stuck in some thoughts from the Five Dysfunctions of a Team by Lencioni. The second discussed the lessons taught by GM’s failure in adopting Toyota’s Lean processes with their NUMMI plant. This one will go through some great lessons I’ve learned from a terrific – and very short and readable – little book entitled “Visible Ops” by Gene Kim. Please, order this book (just $17 on Amazon!) and give it some thought.
“The single largest improvement an IT organization can benefit from is implementing repeatable system builds. This can’t be done without first managing change and having an accurate inventory. When you convert a person-centric and heavily manual process to a quick and repeatable mechanism, the reaction is always positive. Even a partially automated release/build process greatly improves the ability for individuals to be freed from firefighting and focus on their areas of real value. And by making it more efficient to rebuild than repair, you also get much faster systems downtime and significantly reduced downtime.” (Joe Judge, Adero)
I was always struck by the phrase from Tolstoy – “All happy families are alike, every unhappy family is unhappy in its own way.” Turns out that’s true of DevOps as well. Successful companies, it turns out, have some very common threads in terms of IT:
-
High service levels and availability
- Mean Time To Repair (MTTR)
- Mean Time Between Failures (MTBF)
-
High throughput of effective change
- Change success rate >99% (for example, amazon with 1500+ changes a week)
-
Tight collaboration between dev, Ops/IT, QA team, and security auditors
- Controls are visible, verifiable, regularly reported
-
Low amt of unplanned work
- <5% of time spent firefighting – typical is 40%
-
Systems highly automated and hands-free
- Server to System Admins ratio 100:1 or greater (typical 15:1)
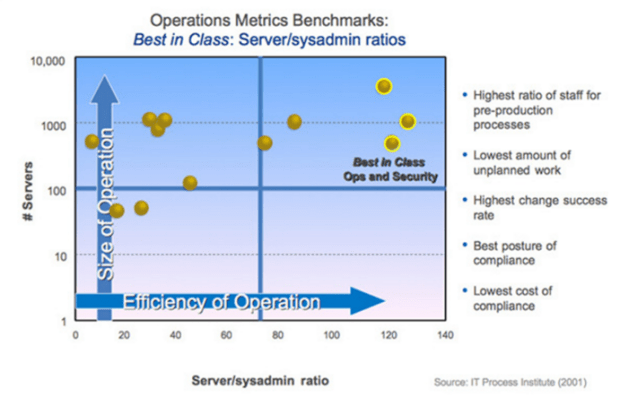
So what are the common factors with the happy families” that have these highly efficient, repeatable RM culture?
-
A change management culture
- Management by fact versus belief
-
All changes go through a formal change management process
- “The only acceptable number of unvetted change is zero.”
- “Change management is important to us, because we are always one change away from being a low performer.”
- “Perceptions of nimbleness and speed are a delusion if you are tied down in firefighting.”
- “The biggest failure in any process engineering effort is accountability and true management commitment to the process.”
-
No voodoo – causality over gut feel
-
Trouble ticket systems – inside each ticket are all scheduled changes and all detected changes with the system.
- This leads to 90% first fix rate and 80% success rate in initial diagnosis
-
-
Human Factors Come First in Continual Improvement
- Strong desire to find production variance early
- Controls to find variance, preventative and detective.
Every unhappy family though is unhappy in their own way. You’ll hear sayings like the following in these “DevOps won’t work for us, we’re unique and special” type organizations:
- “80% of our outages are due to changes – and 80% of the time we take in implementing a repair is trying to find that change” – Gartner
- Data and continual improvement takes a back seat to intuition, gut feel, highly skilled IT Ops staff
- SLA not met
- “Most of our work is caused by self-inflicted problems and uncontrolled changes. Each sprint I start with a blank slate, and each sprint ends with 50% of my development firepower getting sucked away into firefighting.”
- Infrastructure is repaired not rebuilt- “priceless works of art”
- System failures happening at worst possible time, IT’s rep is damaged
- Changes have a long fuse
- One change can undo a series of change(s)
So how does an unhappy family move towards becoming more functional? Gene Kim has broken it down into four logical steps.
-
Phase 1 – Stabilize the Patient
- Freeze changes outside maintenance window
- First responders have all change related data at hand
-
Phase 2 – Find the Problem Child
- Inventory your systems and identify systems with low change success, high repair time, high downtime business impact
- Phase 3 – Grow your Repeatable Build Library
- Phase 4 – Enable continuous Improvement
In a little more detail:
-
Phase 1 – Stabilize The Patient
- Beginning of step for Goal is to allow highest possible change throughput with least amount of bureaucracy possible. No rubber stamping, change request tracking system feeds info to first responders, ensure solid backup plan.
- Inventory applications and identify stakeholders and systems
- Document new change management policy and change window with stakeholders
- Institute weekly change management meetings
- Eliminate access to all but authorized change managers
-
Electrify the fence with instrumentation, monitoring
- you’ll be shocked at what you find!
- this prevents org from falling back into bad old habits, like a rock climber with a ratchet and rope
-
Failure Points
- We won’t be able to get anything done!
- The business pays us to make changes. Not to sit in boring CM meetings.
- We trust our own people – they’re professionals and don’t need micromanaging.
- We already tried that – it didn’t work
- We believe there are no unauthorized changes.
-
Phase 2 – Find The Problem Children
- Analyze assets, find fragile artifacts (use list from Phase 1)
- Must be fast. Can’t freeze changes forever.
- Soft freeze, where truly urgent changes during this period go through CAB.
-
Failure Points
- Pockets of knowledge and proficiency
- Servers are snowflakes – irreplaceable artifacts of mission critical infrastructure
-
Phase 3 – Grow Your Repeatable Build Library
- Create a RM team. (Shifts team to pre-prod activities)
- Take fragile artifacts in priority – create golden builds stored in software library
- Separation of roles – devs have no access to production
- Amount of unplanned changes (and related work) further drops
- # of unique configurations in deployment drops, increasing server/admin ratio
- Mitigated the “patch and pray” dilemma, updates integrated into the RM process for patches to be tested and safely rolled out
-
Phase 4 – Enable Continuous Improvement
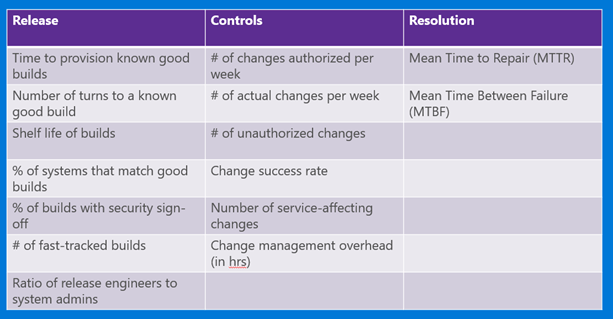
- This has to do with gathering metrics and measuring improvement along three lines – release, controls, and resolution.
-
Release – how efficiently and effectively can we generate and provision infrastructure?
- Time to provision known good builds
- Number of turns to a known good build
- Shelf life of a build
- % of systems that match known good builds
- % of builds with security signoff
- # of fast-tracked builds
- Ratio of Release Engineers to System Admins
-
Controls – how effectively do we make good change decisions that keep infrastructure available, predictable and secure?
- # of changes authorized per week
- # of actual changes made per week
- # of unauthorized changes
- Change success rate
- Number of unauthorized changes
- Changes submitted vs changes reviewed
- Change success rate
- Number of service-affecting outages
- Number of emergency changes or “special” changes
- Change management overhead (measure bureaucracy, lower is better!)
-
Resolution – when things go wrong, how effectively do we diagnose and resolve issue?
- MTTR – Mean Time To Repair
- MTBF – Mean Time Between Failure

4 comments