As many of you know, I’m a huge fan of the work Gary Gruver has done – in particular his book “Leading the Transformation” on his experiences at HP trying to transform a very traditional enterprise. (See my earlier mention of his book on this blog, here.) His newest work is out – Starting and Scaling DevOps in the Enterprise. I am recommending it very highly to all my customers that are following DevOps! I think its unique – by far the best I’ve read so far when it comes to putting together specific metrics and the questions you’ll need to know in setting your priorities.
Gary notes that there are three types of work in an enterprise:
-
New work – Creating new features or integrating/building new applications
- new work can’t be optimized (too much in flux)
- Best you can hope for here is to improve the feedback loop so you’re not wasting time polishing features that are not needed (50%+ in most orgs!)
-
Triage – finding the source of defects and resolving
- Here DevOps can help by improving level of automation. Smaller batch sizes means fewer changes to sort through when bugs crop up.
-
Repetitive – provisioning environments, building, testing, configuring the database or firewall, etc.
- More frequent runs, smaller batches, feedback loop improved. All the DevOps magic really happens in #2 and #3 above as these are the most repetitive tasks.

Notice of the three types above – the issues could be in one of five places:
-
Development
- Common pain point here is Waterfall planning – i.e. requirements inventory and a bloated, aging inventory)
-
Building Test Environments
- Procurement hassles across server, storage, networking, firewall. Lengthy handoffs between each of these teams and differing priorities.
- Horror story – 250 days for one company to attempt to host a “Hello World” app. It took them just 2 hours on AWS!
-
Testing and Fixing Defects – typically QA led
- Issues here with repeatability of results (i.e. false positives caused by the test harness, environment, or deployment process)
- Often the greatest pain point, due to reliance on manual tests causing lengthy multi-week test cycles, and the time it takes to fix the defects discovered.
- Production Deployment – large, cross org effort led by Ops
- Monitoring and Operations

The points above are why you can’t just copy the rituals from one org to another. For any given company, your pain points could be different.
So, how do we identify the exact issue with YOUR specific company?
-
Development (i.e. Requirements)
-
Metrics:
- What % of time is spent in planning and documenting requirements?
- How many man-hours of development work are currently in the inventory for all applications?
- What % of delivered features are being used by customers and fit the expected results?
- An important note here – organizations often commit 100% of dev resources to address work each sprint. This is terrible as a practice and means that the development teams are too busy meeting preset commitments to respond to changes in the marketplace or discoveries during development. The need here is for education – to tell the business to be reasonable in what they expect, and how to shape requirements so they are actual minimum functionality needed to support their business decisions. (Avoid requirements bloat due to overzealous business analysts/PM’s for example!)
-

-
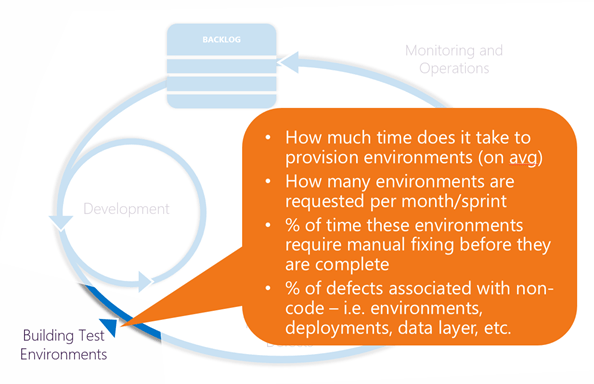
Provisioning environments
-
Metrics:
- How much time does it take to provision environments (on avg)
- How many environments are requested per month/sprint
- % of time these environments require manual fixing before they are complete
- % of defects associated with non-code – i.e. environments, deployments, data layer, etc.
- The solution here for provisioning pinch points is infrastructure as code. Here there is no shortcut other than developers and IT/operations working together to build a working set of scripts to recreate environments and maintaining them jointly. This helps with triage as changes to environments now show up clearly in source control, and prevents DEV-QA-STG-PROD anomalies as it limits variances between environments.
- It’s critical here for Dev and Ops to use the same tool to identify and fix issues. Otherwise strong us vs them backlash and friction.
- This requires the organization to have a strong investment in tooling and think about their approach – esp with simulators/emulators for companies doing embedded development.
-
-
Testing
-
Metrics
- What is the time it takes to run a full set of tests?
- How repeatable are these? (i.e. what’s the % of false errors)
- What % of defects are found with testing (either manual, automated, or unit testing)
- What is the time it takes to approve a release?
- What’s the frequency of releases?
- In many organizations this is the most frequent bottleneck – the absurd amount of time it takes to complete a round of tests with a reasonable expectation the release will work as designed. These tests must run in hours, not days.
- You must choose a well-designed automation framework.
- Development is going to have to change their practices so the code they write is testable. And they’ll need to commit to making build stability a top priority – bugs are equal in priority (if not higher than) tasks/new features.
-
This is the logical place to start for most organizations. Don’t just write a bunch of automated tests – instead just a few automated Build Acceptance Tests that will provide a base level of stability. Watch these carefully.
- If the tests reveal mostly issues with the testing harness, tweak the framework.
- If the tests are finding mostly infrastructure anomalies, you’ll need to create a set of post-deployment tests to check on the environments BEFORE you run your gated coding acceptance test. (i.e. fix the issues you have with provisioning, above).
- If you’re finding coding issues or anomalies – congrats, you’re in the sweet spot now!
- Horror story here – one company boasted of thousands of automated tests. However, these were found to not be stable, maintainable, and had to be junked.
-
Improve and augment over time these BATs so your trunk quality gradually moves closer to release in terms of near-produciton quality.
-
Issue – what about that “hot” project needed by the business (which generally arrives with a very low level of quality due to high pressure?
- Here the code absolutely should be folded into the release, but not exposed to the customer until it fits the new definition of done: “All the stories are signed off, automated testing in place and passing, and no known open defects.”
-
-

-
Release to Production
- If a test cycle takes 6 weeks to run, and management approval takes one day – improving this part just isn’t worth it. But if you’re trying to do multiple test cycles a week and this is the bottleneck, absolutely address this with managers that are lagging in their approval or otherwise not trusting the gated testing you’re doing.
-
Metrics
- Time and effort to release to production
- Number of issues found categorized by source (code, environment, deployment process, data, etc)
- Number of issues total found in production
- MTTR – mean time to restore service
- # of green builds a day
- Time to recover from a red build
- % of features requiring rework before acceptance
- Amt of effort to integrate code from the developers into a buildable release
- For #1-4 – Two areas that can help here are feature toggling (which you’ll be using anyway), and canary releases where key pieces of new functionality are turned on for a subset of users to “test in production.”
- For #5-6 – here Continuous Integration is the healer. This is where you avoid branching by versioning your services (and even the database – see Refactoring Databases book by Scott)
- For #7-8 – If you’re facing a lot of static here likely a scrum/agile coach will help significantly.

So – how to win, once you’ve identified the pain points? You begin by partitioning the issue:
- Break off pieces that are tightly coupled versus not developed/tested/deployed as a unit. (i.e. HR or Purchasing processes)
- Segment these into business critical and non-business critical.
- Split these into tightly coupled monoliths with common code sharing requirements vs microservices (small, independent teams a la Amazon). The reality is – in most enterprises there’s very valid reasons why these applications were built the way they are, You can’t ignore this complexity, much as we’d like to say “microservices everywhere!”
I really admire Gary’s very pragmatic approach as it doesn’t try to accomplish large, difficult things all at once but it focuses on winnable wars at a company’s true pain points. Instead of trying to force large, tightly coupled organizations to work likely loosely coupled orgs – you need to understand the complex systems and determine together how to release code more frequently without sacrificing quality. Convince these teams of DevOps principles.