It’s a Friday; a good time to reflect and think a little about what I’m grateful for, and what I’ve learned. I wanted to share with you a little story and what it taught me about myself and how to create lasting change.
In November of 2018 I went in for a routine checkup to my doctor. It had been a while – like five years – since my last visit. A few days later I got the news: I had full-blown Type 2 Diabetes. I go into this more in my book, but this was shocking to me, and I went through all the stages of denial, anger, and guilt. Guilt especially – diabetes is a lifestyle disease. I had done this to myself, with too much pizza and beer, too much time on the couch.
While I was struggling with coming to grips with my new limitations, I found two amazing resources: “Tiny Habits” by Dr BJ Fogg, and the book “The Power of Habit” by Charles Duhigg. Both are game changers. Finally, I realized why all the grand resolutions and big pushes I’d made to change my lifestyle had ended up in failure, and how to create change that sticks.
Basically, I was trying for a “Big J” – an all out effort, based on a big New Years Day type resolution. “I am going to lose 30 lbs in 3 months!” To do this, I’d embark on all-out ‘personal transformations’ – radical diets, 2-hour gym torture exercises. You know the deal! Well, guess what – maybe a few weeks later, or a month at most, I’d be back on the couch – discouraged, depressed. What had happened?

Interestingly, a friend of mine had a similar “now what?” moment – when a doctor told him he needed to change or he’d be dead in ten years. My friend went home and decided to try something he liked – getting on a bike. So every day when he got home, he’d bike 3 miles from his home. This was an easy, low-effort habit to start with. After a month or so, he started going for 5 miles… then as far as 10, on weekends. Then he joined a riding group. Three years later, he’s dropped thirty pounds – all by doing something he likes, starting small, and gradually ramping up his positive habit.
Too much change, too fast, is a sure recipe for failure. It takes a significant amount of energy to get up and go to the gym for 2 hours, for example. I’ll bet, after a week or so, you’ll hit snooze on your alarm clock and go back to bed – or a friend will come to visit – and that speed bump will leave you right back where you started, frustrated and discouraged.
Both Charles Duhigg and Dr Fogg point out that like any other chemical reaction, it requires energy to start anything new and overcome inertia – something called “activation energy”. Lowering that activation energy is the key for success. So, you might do something simple – like lay out your clothes the night before, so its easy to get to the gym. Or you could start with a 10 minute a day goal in the gym. The point is patience. It took you years to get to this point; it’ll take you years to dig your way out.
I’ll repeat those three common factors in failing to create change:
- Trying too much change too fast.
- Not planning for failure. (Something is going to break your routine. What then?)
- Thinking in terms of big outcomes and aggressive goals.
But the point is, what you are trying to do is not based on an outcome. You aren’t thinking about losing 30 lbs for example. You’re trying to establish a habit, one that sticks. Dr Fogg for example started with doing a single pushup every time he went to the bathroom. Five or 10 pushups would have been too much – a single pushup was just right for that low activation energy target. And a year later – lo and behold, he’s doing 50 pushups a day, easily and without much effort.
So to create lasting change, we want to change that big “J” shape to a bunch of little J’s. Something like this:
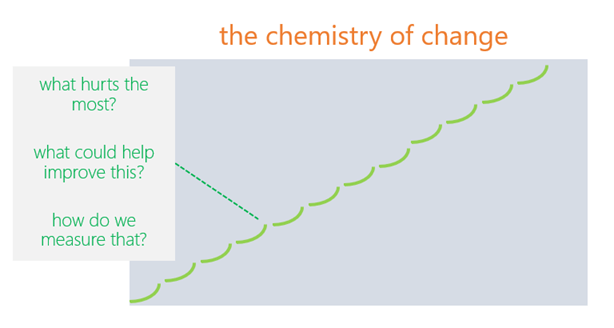
Change means risk, and risk means… well, you know. A lot of companies attempt the “big push” like this – calling it a “DevOps transformation”, or a Digital Transformation, or a Cloud Migration. Most will end up in failure, and the reason why is simple: too much change is happening too fast, and often their measures of success are targeting outcomes. They’re not thinking about habits, and they’re not taking into account the constraints of the enterprise. Put simply, change means risk – and most enterprises have a long successful history of operating in a certain way. A company like that simply does not pivot on a dime.
That’s why you’ll see many of the people presenting at DevOps events working elsewhere a few years later. Change is risky. If we fail in financial goals, we end up in debt to credit cards, discouraged. If we fail in health goals, end up on the couch, frustrated, apathetic, risk health. And if we fail in managing change for our company, make promises we can’t deliver on, that’s a career ending decision.
Here I have to give a shout out to my favorite local gym, 3 Peaks Crossfit. About 8 months ago, I started going, and I hated every day. Some weeks I could only go a few times – but I told myself I’d give it a year to see if I could make this one habit stick. They do a few interesting things:
- They are all about building habits. So it’s encouraged to sign up for classes, so you’re accountable – and to come in as often as possible. Daily is best.
- They have a whiteboard on the wall, where you write down what you lifted, or your time. It changes every day, but over time you can clearly see progress.
- The workouts can be tuned so that anyone at any fitness level can participate. Some people do full-on pullups – others stay on the ground and swing their legs. But, everyone is moving, and no one is stretched too much beyond their limits.

Think about how to make your goals small and achievable. Remember the three keys for success with lasting change:
- Small and achievable
- Simple and clear
- Habit oriented, not about outcomes.
What does that look like in DevOps? It could look something like the following:

I just pulled out a few sample limiting factors, and what might help address that pain point. But making this even simpler – if we treat the delivery pipeline like a garden hose, the problem COULD BE in the middle somewhere. Say it’s not using version control for our environments (DevOps has been defined as ‘coding for Operations’), or infrastructure as code. Or maybe it’s a worthless or missing test layer, so our deployments constantly fail. But quite often we find it’s the beginning or the end of the hose that’s the problem. Maybe we’re making guesses on what features will be valuable, so 75% of our development is being wasted. (Imagine being able to multiply your dev staff by 4x! That’s what HDD can offer.) Or we have no blameless postmortem process, so bugs keep getting swept under the rug and problems keep getting repeated. Or there’s no telemetry or monitoring to knock down problems quickly and keep our availability up.
Enough with the nerd stuff though. Getting back to that gym, and what makes it special – they’ve got a list of values on the wall. It calls out specifically that negative talk, about ourselves or others, is not allowed. Crossfit recognizes that out of our thoughts come our abilities. So let’s be careful about labels. If we think and say things like:
- “I’m stuck in a rut.”
- “I never get ahead.”
- “I’m lazy.”
- “I’m incompetent.”
- “My boss hates me.”
- “I can’t because…”
We are creating a negative feedback loop, reinforced by the language and labels we give ourselves. But if we say:
- “I love learning.”
- “I’m capable of anything.”
- “I always do my best.”
- “I’m a great teammate.”
- “In this one area I can…”
Whoa, that’s a different story! That’s a self-reinforcing, virtuous cycle. The fact is, ANYTHING is possible with enough practice and consistent effort.
Anyway, that’s my positive thought for this Friday. You can do ANYTHING if you set yourself up for success, one habit at a time.
Want video or audio of this? Check out our podcast using Apple, Google, or the podcast host of your choice – and also on my Youtube channel. And, of course, there’s more like this in my book. Enjoy!






