Connect() 2017 is all done and wrapped up for the season. If you weren’t able to make it – as I wasn’t (sniffle) – all the content is available on demand. Click here for an overall list of DevOps focused talks.
I wanted to post a little about one of the great webcasts I viewed this morning, Agile Project Management with VSTS, with Aaron Bjork and Sondra Batbold. This is a really great walkthrough of the full capabilities – including some hawt new features – coming up in Visual Studio Team Services (VSTS). Below are the key features I noticed – broken down by where they appear in the webcast so you can skip to the good stuff.
-
5:09 – Notice the custom Kanban board, with columns for Backlog | Dev Design | Implementing | Code Review and Verify | Closed. There’s a definition of done showing the team’s standards on the info icon – in this case “doing” means fully designed and implementation started; “done” means unit tests written, fx tests updated, and its ready for code review. Nice as well to show the WIP limit on the top right. (Side comment, I love Kanban and how it helps us avoid the myth of multitasking by limiting our Work in Progress. I actually use this at home so I don’t get overwhelmed with my chores around the farm! I do feel, very strongly, that Kanban should be the default starting place and maybe the endpoint for 90% of the teams out there struggling with their Agile implementation.)

- 6:40 – using swimlanes to separate out important items. (Settings icon, Board > Columns)
-
8:05 – Setting a styling rule to have high priority bugs turn red (for example). You can also add tags, if the priority is high enough – and highlight in pink.

- 10:11 – Click on lower left corner of board to add tasks
- 14:14 – “my activity” query for busy project managers off the Work Items hub.
- 14:42 – Scrum team setup with 1 week sprints. Notice the division of work here, from New | Next Sprint | Current Sprint | End Game | Closed.
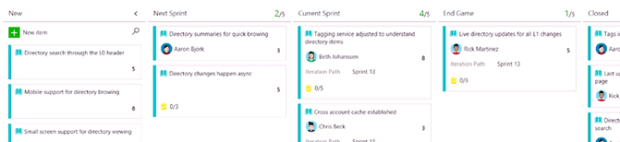
- 17:02 – Most scrum teams focus on velocity – the forecasting feature.
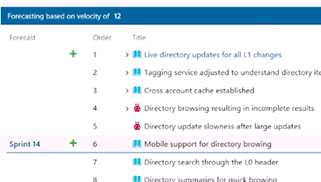
- 19:38 – Adding a column to the backlog (customizing display)
- 20:59 – Capacity planning. Note what it says at 21:34 – “Note this feature is for you and your scrum team, not for management to look down on you. This allows you to make a strong commitment to the upcoming sprint.”

- 22:15 – task board and burndown chart you can use on a monitor in your daily standups (DSU’s)
- 23:49 – filter by person (to show your work only for example, I use this all the time)
-
24:15 – dashboards. Check out the list of widgets in this nice display –
- current sprint
- burndown
- cycle time (closed / new / active) – i.e. “how long it taking us to start working on an item”? this is a key pain point mentioned in the Phoenix Project.
- Stories by state
- Team velocity – in this example it shows the team improving in their completion rate by doing better planning.
- KPI’s – including Open User Stories, Active Bugs, Active Tasks, Ready for Testing, Completed User Stories
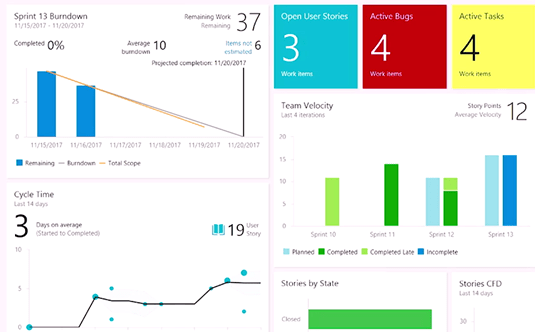
- 25:38 – Very configurable new burndown chart vs the OOTB widget.
- 28:31 – Delivery Plans – a new feature showing work across all teams. In this case we’ve got three teams working on different schedules. You can expand this to dig into work being done by a specific team, and zoom in/out.
-
31:29 – Plans – You could put a specific milestone – say a release date – on the chart.

- 32:19 – How does Microsoft use delivery plans with their product teams? In the VSTS case, the leads for all 4 teams meet regularly. They talk about what’s currently going on, what’s 3 weeks out. There’s a lot of “A-Ha!” moments here as cross dependencies get exposed. (Pro tip – use “T” to show succinct view)
- 33:32 – new Wiki feature. (Could this take the place of an emailed retrospective?) You could add a new sub page, etc. Very customizable, I like it. Use a pound (#) to add a reference to another work item.
- 35:53 – Add a new work item type to a custom template inherited from the standard Agile template. In this sample they force people to add a custom color and a icon to a new work item to visually differentiate it from others. (I’m questioning this one, does this really add value?)
- 38:43 – Adding a “followup owner” so code reviews are enforced.
- 40:30 – Queries are simplified and redesigned
- 45:00 – Customizing the dashboard, in this case show a different color if WIP is excessive.
- 47:15 – I love this part – Extensions. There’s a lot of custom extensions for builds, burndowns, etc. They walk through two paid extensions, one for the Backlog Essentials (quick in-place edits of a work item from the list, why isn’t this standard??!) and TimeTracker (for orgs that want to report/track time on dev hours) These are all available from the shopping cart icon, top right in VSTS. Note you need to add the Analytics extension to really kick up your burndown chart’s capabilities, see Greg Boer’s recent presentation on Channel9 including PowerBI features on Channel9.

-
51:12 – Q&A:
- Can we display a burndown chart across projects? (not yet, but soon) Note the comment at 54:13 – “I will tell you – we recommend one cadence to rule them all. We run on a 3 week cadence for our 700 people. It adds so much simplicity and clarity when we’re talking about dates.”
- View Only (vs modify) permissions yet? (that’s coming also, we are working on joining multiple accounts together so we can view on an org level). Note on permissions, MSFT uses Area Path permissions for security to hide work on sensitive projects (a la HoloLens)
- Hey, there’s lots of clutter on my PBI’s. Can we clean this up? (We’re working on a Personal view so you can pin only the fields a particular person is working on.)
Anyway that’s a lot of content for me to go through and think about. Should keep me busy for the next week or so as work on my book progresses!
Other Connect sessions I will be checking out –
General:
- Azure DevOps Simplified with Brian Harry – where we are going and the great Abel Wang runs through a compelling demo of how easy it is to set up a complete release pipeline.
- DevOps for any language and any platform – Donovan Brown and Jessica Deen deploy using any language on any platform, including Windows, Linux, mobile and containers.
- Zero to DevOps with Visual Studio Team Services – Abel Wang, DevOps from scratch (may also watch this)
Database
- Database DevOps for .NET Developers with SSDT and SQL Server 2017 – Brian Randell – SQL CI/CD to Azure
- DevOps + SQL – Eric Kang, database CI/CD automation
- Database DevOps with SQL Server Data Tools and Team Services – Eric Kang, automation of app and database CI/CD pipeline using Visual Studio Team Services
Containers
- .NET development in Azure with VSTS – Jessica Deen, automate to Azure container
- Container based deployments with Docker, Kubernetes, Azure and VSTS – Jessica Deen, running containers in a Docker Swarm or Kubernetes cluster from a CI/CD pipeline in VSTS.
- Use SQL Server 2017 in Docker containers for your CI/CD process – Eric Kang, running SQL Server 2017 in Docker containers, combining an app and a SQL Server database as a service.
Release Management
- Build in Azure and deploy on-premises with Visual Studio Team Services – Steven Murawski, on prem builds
- Deploy with RM Greenlighting Capabilities – Abel Wang, greenlighting (gated approvals)
- Continuous Monitoring across your DevOps workflow – Mike Gresley, monitoring apps using Application Insights
Source Control
- Getting Started with Git in VSTS – Edward Thomson, std Git workflow intro. There’s also webcasts on Pull requests, converting from Subversion, Git at Scale, but I may not buy out the time for these.
Testing
- Testing capabilities in Visual Studio Team Services – Abel Wang, testing in VSTS.