DevOps is a worthwhile investment to make. I think sometimes people hesitate, because it can be some time away from your regular duties to invest in new skills, to start doing test-driven development, to move your infrastructure over to a configuration management system like Puppet. But what I’ve found is, it’s really a worthwhile investment that not only improves the quality of what’s being built, but the job satisfaction of everyone who’s doing it. Bess Sadler, Digital Library Systems at Stanford University
Before a few months ago, I wasn’t sure what DevOps was in reality and I was a little suspicious of the term. Wasn’t ALM enough? I was kicking my bits out to QA every day using continuous integration – what did it matter if it took a few weeks more to get out the door to production? That’s the Ops people’s responsibility, not mine!
Without knowing it, I was stumbling up against a major shortcoming of ALM. Ken Schwaber said the purpose of Agile was to produce potentially releasable software as quickly as possible. And we took that and ran with it. I remember one project where we thought we made AMAZING progress when we kicked out a very robust and interactive survey site for our customers in only two sprints – getting it out the door to QA in record time. But what did that really mean for our customers, if it took Ops 10 weeks to build out the environments to support it on production? As devs, we failed to treat Operations and infrastructure as equal partners in the process – and we missed an opportunity that cost the business valuable time to market.
“To Heck With Them, I’ll Do It Myself” – the Rise of Shadow-IT
As a result of this friction, something called “Shadow-IT” has arisen over the past few years. If provisioning software can take weeks or months to implement, it makes any thought of Agile development a pipe dream. It’s become increasingly more easy for developers to build up VM’s and entire QA/PROD environments on the cloud. When a developer is faced with an apparently stubborn and slow-moving Ops organization, it’s understandable that some have made the decision to take on the job of building out production environments and doing an end-run around Operations.
There’s some psychology at work here. Fundamentally developers have a core set of values and a background that’s very different from Operations/IT. Developers are focused on agility – producing features as quickly as possible and getting them out the door. Devs are evaluated by their ability to produce, and produce quickly. Operations teams typically want to make a plan and execute to a plan – they are evaluated by their track record with stability and security. Stability and agility are on opposite sides of the spectrum, my friends.
As a developer I was hurting myself by not thinking more of the end goal. And put yourself in the shoes of that poor Ops guy that’s given an extensive manual setup script six days before launch. If that first war room deployment is a train wreck with lots of on-the-fly adjustments and long hours, how eager will they be to work with me in the future? This knocks CI right out of the picture, since they’ll think, “If I deploy more things faster to prod, won’t I be shooting myself in foot?”
It comes down to our definition of done. We aren’t done when it builds on our machine and we huck it over the fence. As software cratsmen, our job is to deliver value – and value is software running in production, period. So, for DevOps to work, it’s more than just RM or tooling. We as developers need to be more interested in the end product, and IT needs to be more interested in the beginning.
I believe the above attitude – which I have fallen into several times in my career – is very shortsighted. Operations and tracking down performance bugs or environmental anomalies is a specialized set of tasks – and one that I’m ill-suited for. I grit my teeth and walk through Perfmon logs when I have to – but it’s not a core skillset. Shadow-IT is NOT the answer in improving our time to market long term – and as we called out above, that return trip of information and feedback on usage is suddenly missing, crippling our development efforts.
DevOps Comes on the Scene
Back about six years ago, in 2009, a group of people noted that the shortened release cycle was causing a lot of friction – it exposed a gap between the people writing the software and those responsible for deploying it to production:

The old way of doing things with monthly and quarterly releases worked OK, but with daily releases with CI the Operations side of things is falling behind. Some key points exposed by the above graphic:
- We needed tooling to automate releases as much as possible – including tracing and approvals
- The old way of “it works on my machine” or being surprised when sites weren’t available – being told reactively with SCOM or worse by external customers – was a no-go.
- We were having problems closing the feedback loop – that’s the top part of the cycle. Especially with disconnected business owners, it was VITAL to receive as much specific metrics as possible – from Ops, from usage patterns on the app itself – so we’d know what features we needed to prioritize for the next sprint.
To fill the gaps, the concept that came to be known as DevOps came into focus:

Let’s break this down by People, Process and Tools:
-
People
- Stronger collaboration not just with Ops teams but also QA, BA’s and end user community
- Bugs are knocked down immediately not left to mounting technical debt
- Stronger focus on continuous learning – versus unattainable “zero defect” or unproductive manual Change Board meetings
-
Process
- Unit testing and functional/integration testing becomes a part of each release cycle.
- Incident management feeds bugs back to dev team
- Release branching simplified and feature branching verboten
-
Tools
- Release management to handle moving bits out the door
- Tools to handle provisioning of environments – infrastructure as code
As you can see, the assumption many people have when they hear the word “DevOps” – “Oh, that means RM” – isn’t anywhere close to complete. It’s like saying that ALM is having your code in source control. And the goal we have in mind isn’t some kind of unrealistic paradise where we are all around the campfire telling stories and roasting marshmallows. As I heard recently by an Agile architect, “DevOps does not mean Operations and Devs hugging each other”. What he meant was, the point was getting it out in production as quickly as possible – and getting as much metrics back as possible. It’s more about efficiency than it is about making friends.
So there’s a lot to that formal definition of DevOps – “The collaboration of IT Operations and developers in deploying new software to benefit the business.”
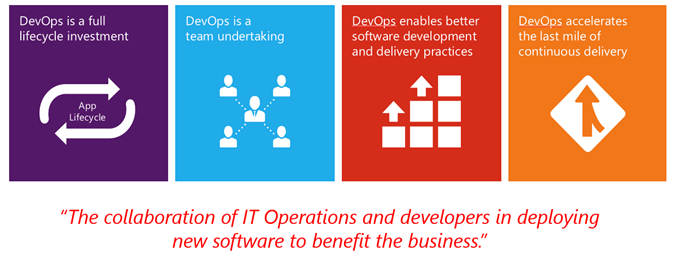
The Importance of Culture
So if you want to “be DevOps”, don’t create a separate team and don’t search for some magic process or methodology. …your operations team to start speaking up and working with your development team about what could be done to reduce the operational complexity of the software. Figure out how to make your software easier to configure, easier to deploy, and easier to operate in general. Likewise, your development teams need to seriously listen to the operations group. They need to treat the operations team’s concerns just like they would treat any end-user feature request or bug request. After all, your operations team is simply another type of user of the development team’s software. (from http://www.devopsonwindows.com/it-takes-dev-and-ops-to-make-devops/ )
Changing culture is hard. For many developers, their individual influence won’t be enough to make headway in this change. (Although, do check out the Phoenix Project and the great Damien Edwards video “You Can’t Change Culture, but You Can Change Behavior and Behavior Becomes Culture” in my links below.) Based on personal experience, I believe DevOps does not work as a grass-roots or bottom up. You will need a CxO level advocate or an architect as a champion to move ahead.
Start out with a realistic view of what’s possible/achievable given the organizational makeup. Flat organizations do have a better track record of success. And keep in mind the important elements of culture your organization will have to demonstrate:
- Collaboration
- No-Blame Postmortems
- High-trust culture
- Experimentation and risk
- Strong focus on continuous improvement
- Good information flow and bridging between teams
I talked yesterday evening with someone that had an architect that realized their cloud-based infrastructure was costing them thousands of dollars monthly. He told the development team that they were going to be taking DevOps seriously – and that their environments would be completely disposable. Every night they would tear down their machines to a bare minimum – and every morning they’d rebuild them again. It worked brilliantly. That’s the kind of game-changer you need on your side.
A study by Westrum in 2004 divided organizations into three general categories, based on their orientation and base characteristics. Is your company Pathological, Bureaucratic, or Generative?
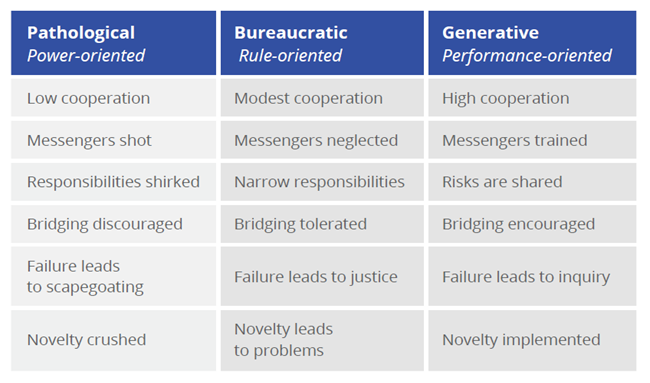
(courtesy Puppet Labs)
If your organization is Pathological, the best advice I can give is to focus on what you can do, and keep your own house in order. Have CI and RM in place – but know in advance, your odds of instituting meaningful DevOps are fairly low. This is because these types of organizations do not lend themselves well to the cross-team collaboration that will be vital for your success. Bureaucratic organizations are relatively friendlier, but there still will be a significant amount of inertia for you to overcome. Forming a DevOps Center of Excellence here or bringing in outside consultants to help sway decisionmakers may be a difference-maker here. If you’re in a Generative organization, congratulations – your pilot efforts will likely be the first step on a successful road to DevOps that will make your work-life as a developer much, much happier. Automating tedious tasks and not getting drowned in firefighting or unplanned work means a happier YOU.
History reveals some seemingly counterintuitive facts about DevOps adoption rates – Curiously enough, larger organizations and Windows-based vs open-source orgs have a higher rate of success in adopting DevOps. Looser open-source or smaller teams may not have the consistent level of discipline it takes to make DevOps stick. (Maybe too much freedom is a bad thing?) And, some of the best success stories come from the worst starting point. Pain is a powerful catalyst for change. If things are going well or even just OK, there’ll likely be little impetus for something as far-reaching as DevOps.
In discussing with management the key points of DevOps, stress the following benefits:
- Our ability to ship features quickly and speed of deployment will rise dramatically.
- We’ll be able to react quicker to your feedback as stakeholders and incorporate them into our feature prioritization.
- We’ll be able to recover from failed deployments quickly and have smooth rollbacks.
- Happy cows make better cheese. DevOps practices increase employee satisfaction, which leads to better business outcomes. A strong IT org means a profitable company. DevOps practices lead to a strong IT org. DevOps will lead to a healthier team.
If that doesn’t work, mention metrics. They may not care specifically about RM – but they will care if it drops your defect rate by 50% and increase their profits by 100%. And you can always mention the scare story of Knight Capital, which – by not instituting release management and DevOps earlier, lost $450 million dollars in the course of 90 minutes in August 2012. Studies show that high performing IT orgs are 2x as likely to exceed profitability, market share, and productivity goals. There’s a strong correlation between robust IT organizations and continuous delivery practices and productivity.

There’s other ways to change culture. I’ve heard of some companies seating engineers/ops next to each other, hiring consultant/mediators to streamline implementation, and forcing devs to be responsible with pager duty.
A healthy team = trust. Good feedback loop, crossfunctional collaboration, shared responsibilities, learning from failure. You’ll have a happier, easier, less stressful life as a developer. What’s not to love?
From Zero to DevOps in 180 Days
Here’s a sample recipe you could put together in trying to implement DevOps in your company. We’ll be realistic and pragmatic here, and assume that the first step must be taken by us, the developers – and after a trial period we’ll have Operations teams chiming in for a second phase:
First Phase: Getting Your House in Order (Month 1)
- Devs take first step
-
Basic release management
- Automatic provisioning of clients / config management
- Continuous Integration
- Beginnings of automated testing, version control
- Elimination of feature branches
- Peer reviews begin (NOT external change approval
Second Phase (Month 3)
- No-blame postmortems
- Published dashboarding of automated test coverage
- Regression bugs identified by tests fixed immediately
- Toolset experimentation begins
- DevOps CoE publishes metrics and lessons learned / goals
- Visibility is key
Phase 3: Ops-centric (Month 6)
- Proactive monitoring, analytics, incident resolution
- DevOps awareness / training seminars
- Beginning of automating pain points
- Next up – Build-Measure-Learn or Hypothesis-Driven Development
Wrapping Things Up
We haven’t talked about tooling yet. I’m going to walk through Chef and Puppet Labs integration with Visual Studio in a future blog post, and the same for deploying bits using the new Release Manager application integrated with VS. I have another post on Application Insights as well, which will help you expose to your business partners your test coverage and website performance. All of these things are important – but I believe the people and process side of things are MUCH harder and more fundamental to DevOps than any particular tool you end up selecting.
DevOps means replacing what WAS a vicious, nasty cycle of recriminations and backbiting with a virtuous cycle. Devs work closely with IT early on, stability improves. As stability improves, IT performance improves, and you start getting some meaningful feedback and metrics to prime your backlog. The first step is the necessary one of treating QA people and Operations as equal partners, early on in the process, and getting them involved in the design. Chef environment deployments must be built out along with your code bits, early on – give them the time they need to scale out so they can do their job.
So here’s some closing thoughts on how to make your journey to DevOps as smooth as possible:
Don’t form a single DevOps team. That doesn’t mean don’t begin with a cross-functional pilot team as a proof of concept – that’s actually a good idea – but forming a single DevOps team misses the point. From Jez Humble’s blog: “The DevOps movement addresses the dysfunction that results from organizations composed of functional siles. Thus, creating another functional silo that sites between dev and ops is clearly a poor way to try and solve those problems. (i.e. a cross functional team)”
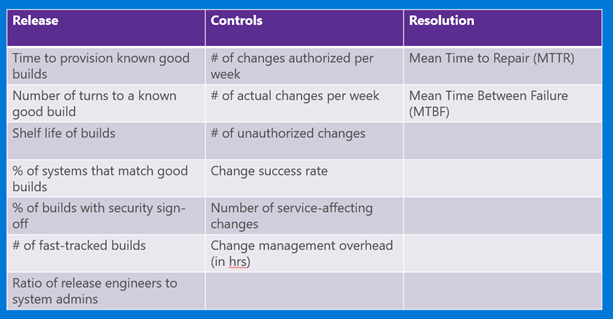
Go slow to go fast. Recognize IT as an investment, and secure management support as a precursor. Start small and grow – gather data, and iterate. Gauge user response, collect metrics on things like MTTR/MTTD, and rinse and repeat.
Encourage experimentation. Propose a change and promise to reevaluate in six months or some other time limit. Make postmortems blameless. Practice root cause analysis (think of the “Five why’s”), and keep a detailed log of events without fear of punishment. Don’t level personal criticism at anyone, and don’t take feedback personally. Managers, it’s up to you to create a culture where it’s safe to fail.
Choose your tools wisely. There’s a variety of RM and infrastructure tooling out there, and each have pros and cons. Whatever you do, make sure the entire group has input on the tool of choice so you have their buy-in. You’ll want an integrated toolset based on loosely coupled platforms – one that can automate all those formerly painful manual steps, and where you can provide visibility and transparency through application monitoring.
Take that Ops handshake seriously. We need to think as devs about how Operations will monitor and support the software we produce. And pay attention to the little things – keep your promises, foster open communication. I have seen in multiple war rooms good and bad examples of how to act when things go wrong. If you behave predictably and calmly when the wheels come off, your Ops team will begin to take your words of partnership seriously.
Don’t go it alone. Incubate your DevOps movement with a Center of Excellence. Fold in your business analyst and business owner, and track metrics. Hold seminars or devops awareness brownbags. Some of the resources below in the links are very helpful – again, I’m referring to the Phoenix Project book in particular.
If you’re having trouble being taken seriously, think about bringing in some help. I worked at one organization for several years as a development lead and became very frustrated at our slow rate of adoption of ALM and DevOps. Once we brought in some Microsoft resources, they were able to hold workshops and chart out a clear path for us that was reasonable in scope and fit our business and cultural background. Within 18 months, you wouldn’t have recognized the changes in the development teams – we had an integrated set of tools and processes that the developers loved, and got our releases out the door much more quickly to the delight of our customers. Having that independent third voice in the room really made all the difference for us in getting our dev maturity level off the ground. Good luck!
Link Goodness – For Devs (specific implementation details)
- Excellent courses available here – http://www.microsoftvirtualacademy.com/training-courses/devops-an-it-pro-guide
- And here: http://www.microsoftvirtualacademy.com/training-courses/assessing-and-improving-your-devops-capabilities
- And get this book – it’s becoming a standard, along with the Phoenix Project from Gene Kim. https://www.safaribooksonline.com/library/view/continuous-delivery-reliable/9780321670250/
- This demo is an excellent walkthru- http://blogs.msdn.com/b/visualstudioalm/archive/2014/11/11/using-release-management-vso-service-to-manage-releases.aspx
- Channel9 videos on DevOps – http://channel9.msdn.com/Tags/edge-devops
- A nifty walkthrough of Puppet integration with Visual Studio Online – http://channel9.msdn.com/Shows/Edge/Edge-Show-110-Puppet-on-Azure
- Brian Keller does a 10-minute walkthrough of RM deployments (excellent for getting started with infrastructure as code) – http://channel9.msdn.com/Events/Visual-Studio/Connect-event-2014/214
- Great list of resources – http://www.itproguy.com/top-2014-microsoft-devops-learning-resources/
- Books that everyone appeared to quote and that seem very influential are the Phoenix Project with Gene Kim et al and Jez Humble’s book on Continuous Delivery. Of the two, if you just want a good yarn, start with the Phoenix Project. For a more technical approach, Jez’s book is excellent.
- http://www.microsoftvirtualacademy.com/training-courses/azure-resource-manager-devops-jump-start
- Great blog site for DevOps – http://www.donovanbrown.com/
For Business People / Architects (more general or on culture)
- A GREAT video on culture changing – “You Can’t Change Culture, But You Can Change Behavior, and Behavior Becomes Culture” http://vimeo.com/51120539 – Damon Edwards
- http://www.computerworld.com/article/2851974/microsoft-study-finds-everybody-wants-devops-but-culture-is-a-challenge.html
- http://www.citeworld.com/article/2115209/development/what-is-devops.html
- “There’s often a gap between devs and operators – devs motivated by innovation, pushing the envelope, and system admins tasked with security/stability. I think of DevOps as the bridge of that gap… since we’ve invested more in Ops, been a lot easier for us to get our services out there and actually delivered…. Expensive and timeconsuming to rollout a new feature, even if meticulously scripted often didn’t get it right – discrepancies between dev/prod systems.” – Bess Sadler, Stanford https://www.youtube.com/watch?v=L9V8oEaZ71I
- The PuppetLabs blog on Devops has a wealth of culture change information: http://puppetlabs.com/blog-categories/devops
- Puppet Labs 2014 whitepaper detailing org benefits of DevOps – this is very thorough: http://puppetlabs.com/sites/default/files/2014-state-of-devops-report.pdf
- MS site on DevOps – http://blogs.technet.com/b/devops/
- The rise of Shadow-IT – “A very tangible, negative side effect of this situation is Shadow IT, where developers create their own ways to deploy and run their solutions, in order to maintain the required speed of change and flexibility, and to respond to ever growing demands. One example of this is cloud technologies with easy-deploy options and pay-as-you-go offers foster Shadow-IT, which frequently leads to the drifting apart of development and operations teams, leading to a Shadow-IT scenario.”
- VM’s and hands-on labs: http://aka.ms/ALMVMs
- Great article on DevOps including a checklist and sumup: http://www.devopsonwindows.com/it-takes-dev-and-ops-to-make-devops/. I love their article on removing config files and the checklist rocks.
- A nice interview with Yelp on how they were able to institute change, focusing on listening, being humble, and understanding the patterns your org has in place before advocating widespread, permanent changes – http://puppetlabs.com/blog/change-agents-it-operations-what-it-takes
- Gene Kim – how do we Better Sell DevOps? http://vimeo.com/65548399
- I also like the no horse crap video https://www.youtube.com/watch?v=g-BF0z7eFoU
- DevOps resources and links – http://www.itproguy.com/top-2014-microsoft-devops-learning-resources/