We commonly find that everyone – and I mean EVERYONE – is in favor of DevOps once they realize how great it is. Entire teams read through “Continuous Development” by Jez Humble or “The Phoenix Project” by Gene Kim and they are full of enthusiasm, ready to change their deployment processes so changes are safer and more repeatable. But then these teams have a “now what?” moment – we know we want to improve our processes, but where to start?
One of the cool things about DevOps is the lack of fuzziness – it is very, very tangible in terms of measuring ROI and tracking progress. For example, check out the very specific metrics you can use below that the thought leaders above have identified as being common traits of highly effective organizations:
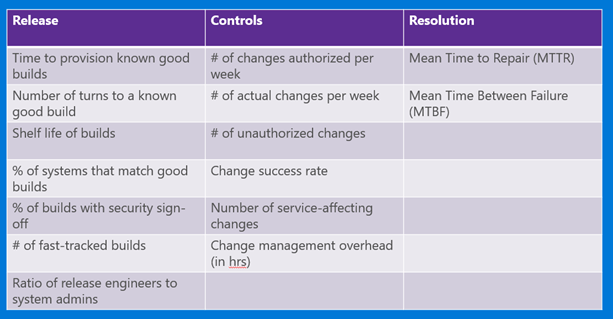
- High service levels and availability (as measured by Mean Time To Repair – MTTR, Mean Time Between Failures or MTBF)
- High throughput of effective change (change success rate >99%)
- Tight collaboration between dev, Ops/IT, QA team, and security auditors
- Controls are visible, verifiable, regularly reported
- Low amount of unplanned work (<5% of time spent firefighting, compared to the average of 40%)
- Systems highly automated and hands-free
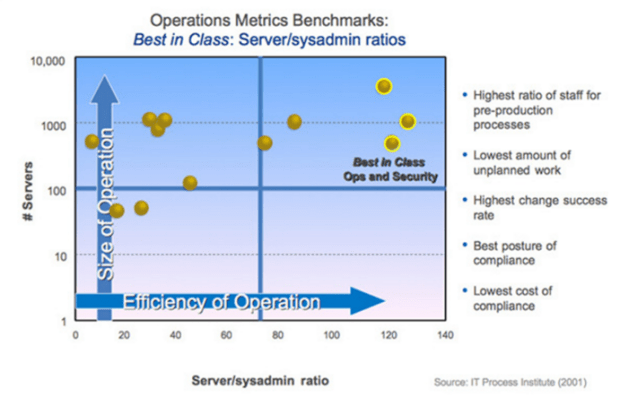
- Server to System Admins ratio 100:1 or greater (average is 15:1)
Those factors above are beautiful because they’re so specific, not subjective. You could – and should – publish these on a dashboard, showing your current state and tracking your maturity level improvement over time.
So, getting down to brass tacks, once we do a baseline and see where we measure up on those 7 key factors above, how do we get to “Phoenix Project” greatness?
You could tackle this in three stages, as follows:
|
Phase |
Steps |
|
Phase 1 – Assessment |
Create a release management team Institute weekly change management meetings Begin gathering and publishing “7 power metrics” (above) Inventory applications and systems, and identify business stakeholders |
|
Phase 2 – Enforcement |
Identify fragile artifacts (Martin Fowler’s infamous “snowflake servers“) Document your policy and change window system by system with stakeholders Remove access to all but authorized change managers Electrify the fence with monitoring / active enforcement of policy |
|
Phase 3 – Stabilization |
Build a library of repeatable builds Feed change info to first responders and trouble ticket system Kaizen (improve and expand metrics gathering, feedback to stakeholders and management) |
These phases aren’t strictly done in a series – there’ll be overlap, and its definitely a monumental undertaking. But, if you love the idea of change management and reducing all the wasted time and stress you spend in firefighting in your company, rest assured – DevOps isn’t just buzz and fluff, it’s tangible and measurable. And it’s a journey that – while it has no true ending – you’ll be very glad that you took. It’ll mean a happier relationship with your business partners and customers, less time tied down in reactive troubleshooting, and more time with your loved ones and families. What’s not to love?
P.S. if you enjoyed The Phoenix Project and want to read up more on your next steps, check out “Visible Ops“. This tiny little book is 100 pages of very specific, tangible steps you can take to inject some DevOps goodness into your own IT organization.