I’ve been doing some demos / walkthroughs of the Azure SRE Agent – thought I would post here the resources I’ve found most helpful. The specific use case here is, “How can I get better / more intelligent alerts for yellow case conditions – like with an endpoint that’s degraded in response times but not yet failed / in a red state?”
- Using the SRE Agent for runbook automation (single best ref) – https://techcommunity.microsoft.com/blog/appsonazureblog/stop-running-runbooks-at-3-am-let-azure-sre-agent-do-your-on-call-grunt-work/4479811
- Extending the SRE agent with MCP for PagerDuty etc – https://techcommunity.microsoft.com/blog/appsonazureblog/extend-sre-agent-with-mcp-build-an-agentic-workflow-to-triage-customer-issues/4480710
- When to use Azure Data Explorer for KQL queries vs interfacing with custom tools (aka Dynatrace etc) – using the MCP connector of course. It describes setting up alerts based on Application Insights, Log Analytics, or Azure Monitor metrics. There’s other pages on Azure observability with SRE agent, RCA, and how persistent memory and kbs are built out. Custom agent patterns in subagents is also excellent. https://learn.microsoft.com/en-us/azure/sre-agent/diagnose-observability
- 3 ways to get more from the SRE agent (smarter patterns vs high frequency polling or using HTTP triggers ) https://techcommunity.microsoft.com/blog/appsonazureblog/3-ways-to-get-more-from-azure-sre-agent/4508993
- set up sre agent with get started refs https://learn.microsoft.com/en-us/azure/sre-agent/overview?tabs=subagent
- This is how you use sre agent for on demand queries and remediation – https://learn.microsoft.com/en-us/azure/sre-agent/diagnose-azure-observability. Note this is on call. The agent doesn’t automatically note and resolve a yellow state in ado from this
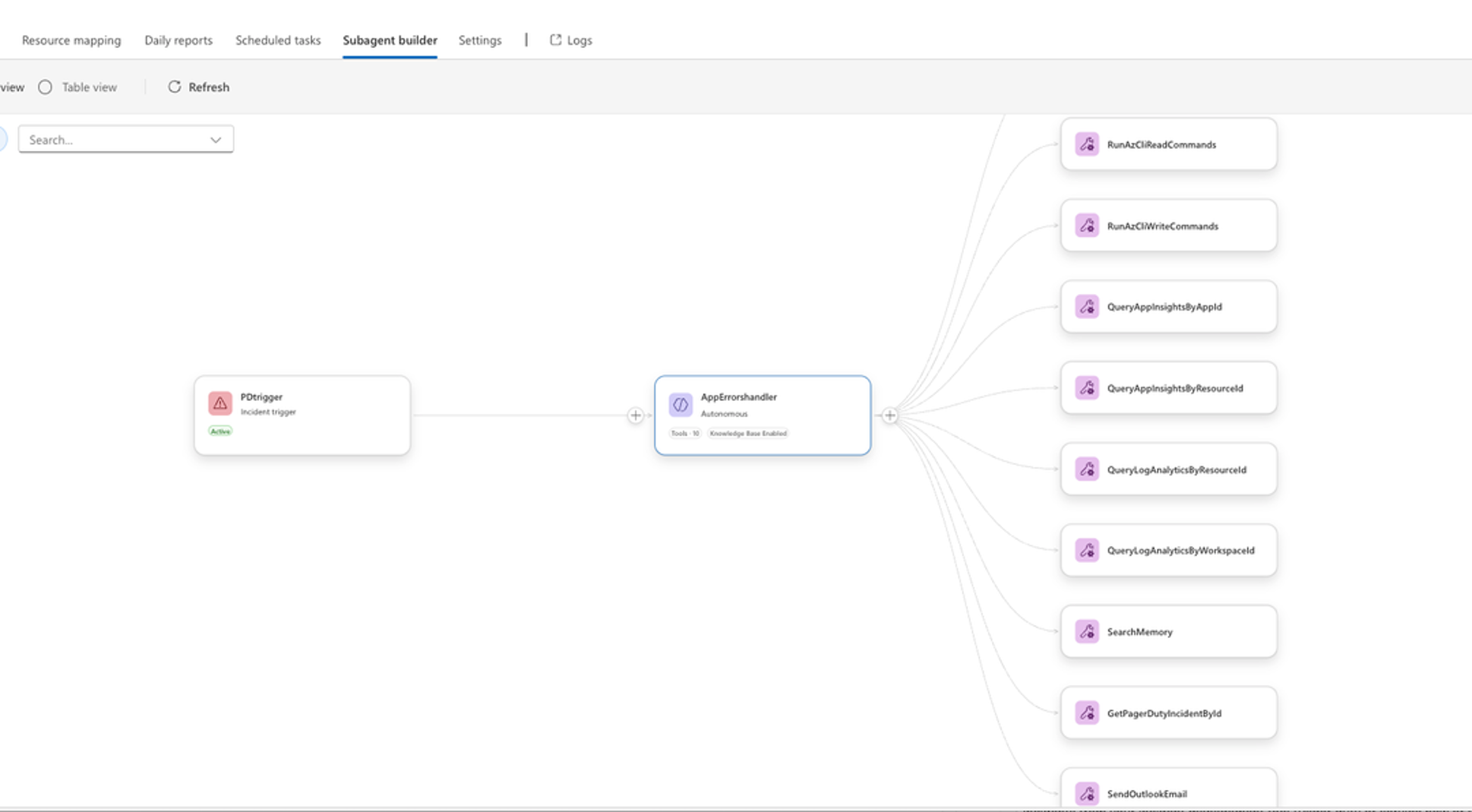
- How do you create a sub-agent in the Azure Portal? https://techcommunity.microsoft.com/blog/appsonazureblog/from-vibe-coding-to-working-app-how-sre-agent-completes-the-developer-loop/4482000)
- Excellent series of Youtube videos here from the program team – https://www.youtube.com/@AzureSREAgent
- for example this one (4 min video) filters out Azure Monitor alerts so they are better triaged. Demonstrates a cooldown window for things like high CPU state. There’s also a weekly hygiene report that’s auto-created.
- also on HTTP triggers – firing on a GH issue type identified by a subagent
- integration with ServiceNow to SRE agent
- Videos
- Proactive .NET reliability with Azure SRE agent – 25 min overview. This is based on deploying a .NET app where something goes catastrophically wrong. Its triggered based on a SwapOperation. But similar workflow in some ways:
- SRE Agent to automate tasks – 15 minute video –Use Azure SRE Agent to automate tasks and increase site reliability | DEM550
- Another video: Azure SRE Agent: Less Toil, More Uptime, Maximum Innovation
- Scott Hanselman Azure Friday: Azure SRE agent with Deepthi Chelupati.
- My friend Jorge Balderas does a very nice 16 min demo. 11 minutes in he shows the alert setup for a backend high response time. Repo links in the comments.
Anyway this is a fun agent to work with and very extensible. Try it yourself!