This is the fourth of a series on DevOps. The first focused on the three ways explored in the Phoenix Project, and I stuck in some thoughts from the Five Dysfunctions of a Team by Lencioni. The second discussed the lessons taught by GM’s failure in adopting Toyota’s Lean processes with their NUMMI plant. The third went through some great lessons I’ve learned from “Visible Ops” by Gene Kim.
“The single largest improvement an IT organization can benefit from is implementing repeatable system builds. This can’t be done without first managing change and having an accurate inventory. When you convert a person-centric and heavily manual process to a quick and repeatable mechanism, the reaction is always positive. Even a partially automated release/build process greatly improves the ability for individuals to be freed from firefighting and focus on their areas of real value. And by making it more efficient to rebuild than repair, you also get much faster systems downtime and significantly reduced downtime.” (Joe Judge, Adero)
So I am putting together a presentation for PADNUG tomorrow on DevOps. I’ve reworked this presentation like three times, and I’ve never been very happy with it. Let’s just say Steve Jobs would have rolled his eyes at something like this:

Look at that crap above. I mean, there’s information here – but way too MUCH information. There’s no way any audience is going to absorb this. I’ll lose them halfway through the second bullet point.
So, I was struggling with this a few weeks ago, trying to come up with a better idea. And I was watching my kids play Monopoly. And I started to think – since there’s no recipe for DevOps, and you can choose your own course, and some amount of it is up to chance or your individual circumstances – well, isn’t that a game? (And isn’t that a more fun way of learning than using an endless stream of bullet points?)
So, DevOpoly was born!

Let’s take a look at this in blocks shall we? 
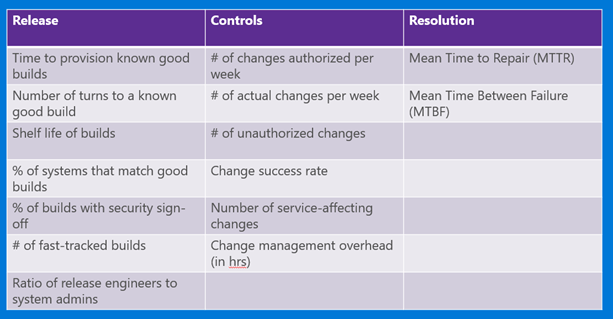
- MTTR – Mean Time to Repair. This indicates how robust you are, how quickly you can respond and react to an issue.
- Stakeholder Signoff – this is after you inventory your applications – instituting any change management policy and change window will require the business to provide signoff.
- Inventory Apps – listing applications, servers, systems and services in tiers. This is a prereq for getting your problem children identified and frozen, see below.
- CAB Weekly Meetings – I used to think these were a complete and total waste of time. In fact several books I have claim that they don’t measurably reduce defects and slow down development – bureaucracy at its worst. But, Gene Kim swears by it – and he thinks it’s a base level requirement for change management culture.

- Versioned Patches – Putting any software patches into source control
- Security Auditing – having controls that are visible, verifiable, regularly reported
- Configuration Management – Infrastructure as Code, a key part of implementing repeatable system builds, using software like Puppet, Chef, Octopus etc.
- Golden Build – The end goal and the building block of a release library, a set of ‘golden builds’ that are verifiable and QA’d. The length of time that these builds stay stable is another metric helpful in determining reliability of your apps.

- Feed to Trouble Ticket – Creating a system where any changes – authorized or unauthorized – show up in trouble ticket for first responders to access. % Success rate in first response in diagnosis is a key metric for DevOps.
- Dashboarding – creating visibility around these metrics (see stage 3 of the Phoenix Project post) is the only way you’ll know if you’re making progress – and securing management support.
- Form RM Team – This is part of the process in moving more staff away from firefighting and early in the release process. Mature, capable orgs have more personnel assigned to protect quality early on versus catching defects late.
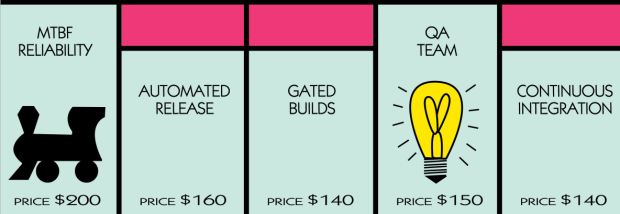
- MTBF – Mean Time Between Failures. As configuration management knocks out snowflake servers and fragile artifacts are frozen, this number should go up.
- Automated Release – creating a release management pipeline of dev bits from DEV-QA-STG-PROD, with as much automated signoff as possible using automated tests, is a great step forward.
- Gated Builds – See above, but having functional/integration testing and unit tests run on checkin is key to prevent failures.
- Continuous Integration – bound up with testing and the RM cycle – having any dev changes get checked in and validated and merged safely with other development changes. (And, remember, CI means the barest amount of release branching possible. It’s a tough balance.)

- Eliminate Access – Actually I don’t know many devs (besides the true cowboys) that really WANT access to production. But, removing access to all but change managers is a key step. And when you’re done with that…
- Electrify the Fence – Have change policy known and discipline the (inevitable) slow learners. Not fire them. Maybe have a few “disappear” in suspicious accidents, to warn the others!
- Monitor Changes – Use some software (like Tripwire maybe?) to monitor any and all changes to the servers.
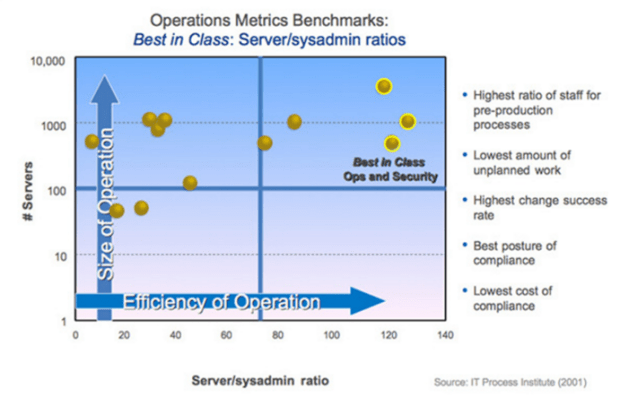
- Server to Admin Ratio – Typically this is a 15:1 ratio – but for high performing orgs with an excellent level of change management, 100:1 or greater is the norm.

- Document Policy – Writing out the change management policy is a key to electrifying the fence and preventing the org from slipping back into bad habits.
- Rebuild Not Repair – With a great release library of golden builds and a minimal amount of unique configs and templates, infrastructure is commonly rebuilt – not patched and limping along.
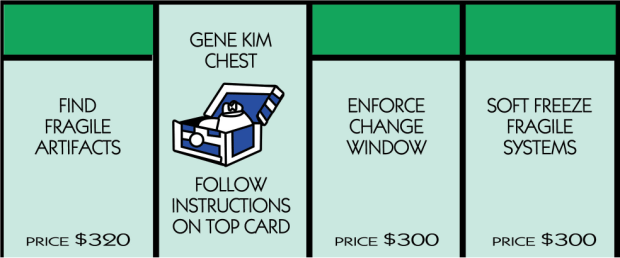
- Find Fragile Artifacts – Once you’ve done your systems inventory, you can document the systems that have the lowest uptime, the highest impact to the business when its down, and the most expensive infrastructure.
- Enforce Change Window – Set a change window for each set of your applications, and freeze any and all changes outside of that window. It must be documented and stakeholders must provide signoff.
- Soft Freeze Fragile Systems – These fragile artifacts have to be frozen, one by one, until the environments can be safely replicated and maintained. This soft freeze can’t last long until the systems are part of configuration management/IAC.

- Accountability – #1 of the two failure points in any change. True commitment and accountability from each person involved.
- Firefighting Tax – Less than 5% of time spent in firefighting is a great metric to aim for. Most organizations are at about 40%.
- Management Buy-In – DevOps can be started as a grassroots effort, but for it to be successful- it must have solid buy-in from the top. Past a pilot effort, you must secure management approval by publicizing your dashboards and key metrics.
Anyway, this was fun. I have some cards on the way for both the Gene Kim Chest – yes, not Jez Humble, but I’m thinking about it – and Chance. Lots of chance in the whole DevOps world.
(I tried this back in August with Life but it never worked by the way.)