I saw the great Hilary Hahn a few days ago at the Oregon Symphony.

The amazing thing about a great concert violinist like Hilary is, they’re fantastic innovators – but always within bounds. You see her rattling off 45 minutes (more or less straight) of beautiful, expressive music – but always within the framework of the larger orchestra. They work in perfect synch.
It’s similar with data warehousing. Twenty or so years into my career, I’ve seen it done wrong multiple times (and right only a few) – and it always comes down to not working within the framework of what analytical databases are designed to do. It’s MUCH cheaper to not try to make up your own organizational definition of what data warehousing is… yet that tends to be a strange kind of compulsion that dogs many DW projects. It’s odd why so many companies choose to go down this route. You NEVER see people quibbling over relational rules with OLTP systems the way we do with analytical stores!
Microsoft’s BI best practices doc is pretty plain vanilla but it does break down DW into these pieces. Failing to understand any of these could mean wasting many, many man-years of effort and millions of dollars in rewrites.
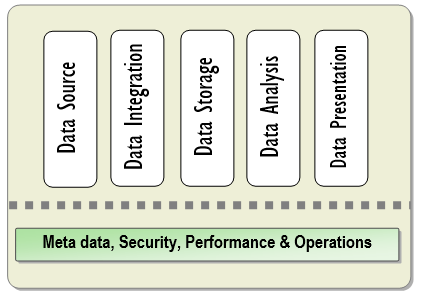
The guide is, sadly, a real snoozer. I’ll break it down in a few sentences:
- Data source is where get our data from. (Duh.)
-
Data integration is a layer that handles data extraction and cleansing.
- It will likely contain both a staging area (a temporary area that houses raw tables from the source) and…
- a loading area (data is now cleansed, validated, transformed, and in a consumable format by a DW).
- A data storage area that holds your dimensional model, including partitions for truly huge tables (yes, you’ll have these). Heavily indexed.
- Data analysis area holding OLAP cubes from SSAS/Cognos/etc and other data mining business logic.
- Data Presentation, including dashboards, flat reports, and moldable data (Powerpivot yay!)
Let’s not get bogged down in details here, but you want to have a staging area that contains your raw tables (and deltas) – this looks EXACTLY like the source data, without relational ties (or even indexes to keep load times to a minimum). Sometimes I drop and add indexes post-load to cut down on ETL times. Your loading area contains consumable objects that are multi-purpose and generic – think a “Products”, “Customers”, and “Suppliers” set of tables, where each row defines a customer, a supplier, etc. This is a relational store but not a OLTP system- you won’t (or shouldn’t) be seeing tons of lookup tables here. Think very flat, breaking some rules with denormalization (i.e. ProductCategory1, ProductCategory2, etc) in the name of performance. The goal here is a set of objects that will be a “one stop shop” of data, hopefully robust enough to survive organizational change with a minimum of bloodshed. For example, currently we’re writing a DW based on an ERP that we’re ‘pretty sure’ will be going away in three months. But I’m reasonably sure, even if we cut over to SAP, that I’ll still have a table of “Items”, “Products”, etc. By having a staging area, I minimize disruption to our users that are becoming dependent on our reports.
So breaking this down even further, for a data warehouse you need:
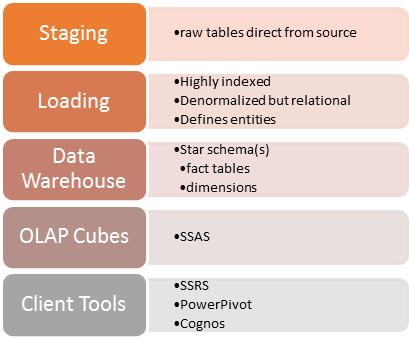
It looks like this:
-
A staging area separate from your source data.
- Format: Raw tables exactly like your source tables, maybe split out using schemas.
-
A loading area that contains a canonical view of your data from an organizational/decisionmaking standpoint.
- Format: Denormalized tables that define specific entities, highly indexed, relational but not hyperrelational.
-
A storage area with your star schema.
- Format: A central fact table(s) and dimensional tables for slicing. You can have many fact tables and several different data stores to present your data in a way that’s most consumable by different departments/groups.
- A set of OLAP cubes for consumption by your client tools.
- Client tools so your users can slice and dice data themselves instead of bogging your development teams down with reporting.
Links
- A GREAT article on high volume ETL and best practices. This is the best one I’ve seen from the MSFT camp – better than the following arch guide(too broad, 6 pages long, REALLY old). http://msdn.microsoft.com/en-us/library/cc671624.aspx
- Notes on Change Data Capture with SQL Server CE: http://msdn.microsoft.com/en-us/library/bb895315.aspx
- http://biarchanddesignguide.codeplex.com/
