For the record, I hate writing console applications. There’s just only so much magic you can pull without a UI to interact with. But, sometimes, there’s no alternative. Take this problem set:
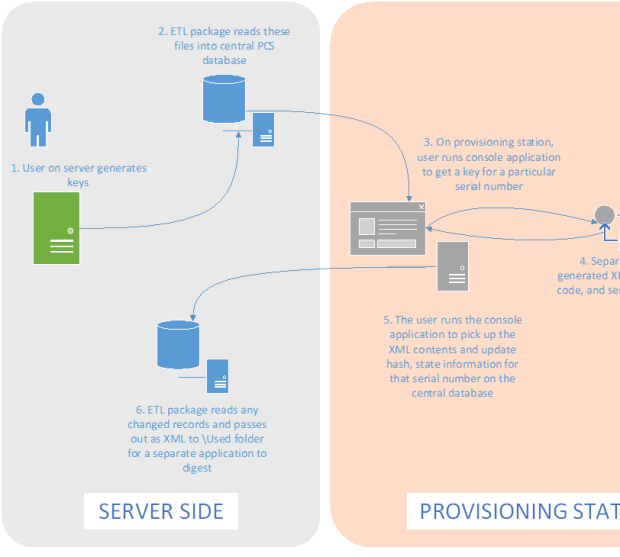
Basically this is a software key provisioning process, where a central server acts as a key repository – holding a pool of allocated keys. There could be 20 or more provisioning stations that need to pull down these keys, one at a time, and assign it to a serial number – add a hash code, and pass it back to the central database for more processing. Above, we have a “user” running this console application – but since it will be hands-free, writing this as an ETL package (on the server side of things, to handle license requests and keep track of assigned serial numbers) for the server side, and pairing it up with a simple console application that can get kicked off command-line on the individual stations made sense.
The actual implementation console-side was relatively easy – so much so I won’t put it here. The console app calls a sproc to receive a datatable and passes it out as an XML file; it’s then decorated with some attributes (updating the process state and adding a hash), and then it’s picked up again and the record is updated back to the database. Pretty beaten down ground there.
The codeset and SQL is here (except the SSIS) – FFKI
However, the Output SSIS package was funky. Following the steps in this post, I added a data flow to output to an ADO.NET recordset, and then added a ForEach loop against that source.
I originally was going to do a database call within the for/each loop – but that seemed wasteful. I mean, the data is RIGHT THERE. Why are we calling the database twice – once accessing the records in table form to form a recordset, and a second time to form XML and output to a file? So, shudder, I used a cursor.

Tough to say this, but the cursor is actually very performant and works fine as the source for a ADO.NET recordset. This can then be set in a variable called @SerialNumber and @OutputXML in a ForEach loop – and that’s what our script works against. Plain and simple, it accepts it – and writes it out to a file. Easy peasy. We could have updated it as a set but I didn’t want dirty records (in case some were inserted or updated to 1 mid-process) – so that’s done as part of the loop individually. (Another solution is to have yet another ToUpdate status of 2 being mid-process and 3 being done.)
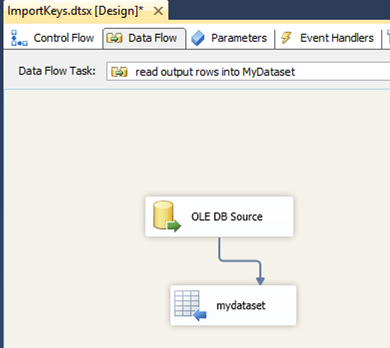
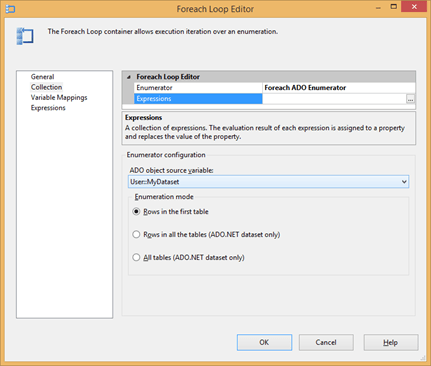
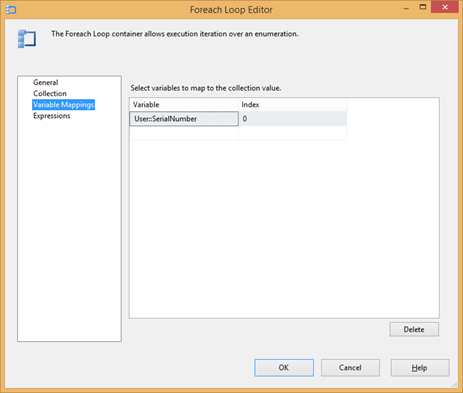
Little things like setting the opening command line arguments I’d forgotten (even how to generate it using csc CMD-side. How quaint!)

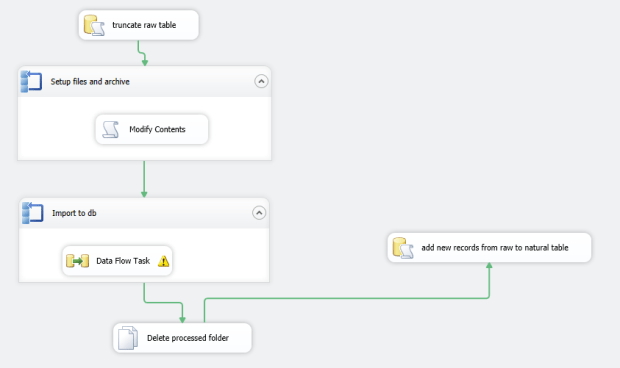
SSIS Package Joy
The SSIS package code. Very spaghetti but it works; I don’t think the structure of VB in SSIS encourages modular programming. (Yes it’s a bit of a copout. I found the same thing true with the console app. If there’s no reuse potential and one Main() entry point, what’s the sense in splitting it out into umpteen methods and separate classes?)
Basic order of events:
- Reads XML from FilePath + FileName using StreamReader
- Adds <Keys> root using FileContent.Replace
- Sets up an archive and process folder using ArchivePath (or ProcessPath) + FileName. We could have used FilePath but it’s possible they’ll want separate file drops in the future.
- Writes to ProcessPath XML file using StreamWriter, and moves orig file to archive destination.
public
void Main()
{
String ErrInfo = “”;
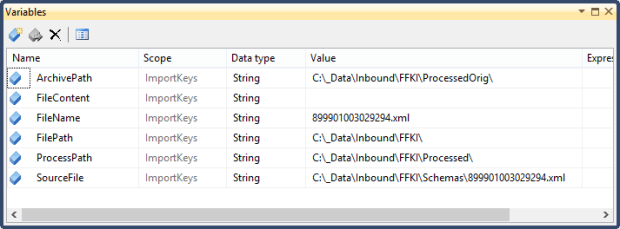
String FilePath = Dts.Variables[“User::FilePath”].Value.ToString()+ Dts.Variables[“User::FileName”].Value.ToString();
//MessageBox.Show(“Filename: ” + FilePath);
try
{
String FileContent; //Variable to store File Contents
FileContent = ReadFile(FilePath, ErrInfo);
if (ErrInfo.Length > 0)
{
Dts.Log(“Error while reading File “ + FilePath, 0, null);
Dts.Log(ErrInfo, 0, null);
Dts.TaskResult = (int)ScriptResults.Failure;
return;
}
//FileContent Before Replace;
//MessageBox.Show(FileContent);
//Find and Replace –> Modify WHERE clause
FileContent = FileContent.Replace(
“<Key>”,
“<Keys><Key>”
);
FileContent = FileContent.Replace(
“</Key>”,
“</Key></Keys>”
);
//FileContent After Replace;
//MessageBox.Show(FileContent);
Dts.Variables[“User::FileContent”].Value = FileContent;
String ArchivePath = Dts.Variables[“User::ArchivePath”].Value.ToString() + Dts.Variables[“User::FileName”].Value.ToString();// +@”\Processed\” + Dts.Variables[“User::FileName”].Value.ToString();
String ProcessPath = Dts.Variables[“User::ProcessPath”].Value.ToString() + Dts.Variables[“User::FileName”].Value.ToString();
//MessageBox.Show(ArchivePath);
//Write the contents back to File
if (File.Exists(ProcessPath))
{
File.Delete(ProcessPath);
}
WriteToFile(ProcessPath, FileContent, ErrInfo);
if (ErrInfo.Length > 0)
{
Dts.Log(“Error while writing File “ + ProcessPath, 0, null);
Dts.Log(ErrInfo, 0, null);
Dts.TaskResult = (int)ScriptResults.Failure;
return;
}
//and move the orig files
if (File.Exists(ArchivePath))
{
File.Delete(ArchivePath);
}
File.Move(FilePath, ArchivePath);
}
catch (Exception e)
{
Dts.Log(e.Message, 0, null);
Dts.TaskResult = (int)ScriptResults.Failure;
}
}
public
String ReadFile(String FilePath, String ErrInfo)
{
String strContents;
StreamReader sReader;
try
{
sReader = File.OpenText(FilePath);
strContents = sReader.ReadToEnd();
sReader.Close();
return strContents;
}
catch (Exception e)
{
MessageBox.Show(ErrInfo);
ErrInfo = e.Message;
return
“”;
}
}
public
void WriteToFile(String FilePath, String strContents, String ErrInfo)
{
StreamWriter sWriter;
try
{
sWriter = new
StreamWriter(FilePath);
sWriter.Write(strContents);
sWriter.Close();
}
catch (Exception e)
{
MessageBox.Show(ErrInfo);
ErrInfo = e.Message;
}
}
Links of Note
- I love this http://www.toptal.com/nodejs/why-the-hell-would-i-use-node-js – basically Node.Js works great for highly interactive two-way communications between servers and clients. Think chat, building an API on top of an object model, queued input (RabbitMQ), data streaming (processing videos while they’re being uploaded), and application/system dashboards that rely heavily on realtime graphics. It’s NOT great for relational db backends or where there’s heavy server-side demands – here Ruby-on-Rails or good ol’ .NET is a better choice. That being said, I really can’t wait to dive into the new Visual Studio plugin for Node.js.
- This example uses outmoded coding (ConfigurationSettings.AppSettings) – and the config doesn’t compile if you use it in this way. Moving AppSettings to the appropriate place and then building works in debug mode, but when you compile it run-time it shows as a blank. http://docs.huihoo.com/enterprisedb/8.1/dotnet-opendbconnection.html
- This example moved configSections before appSettings node to fix. this also didn’t help. http://social.msdn.microsoft.com/Forums/vstudio/en-US/46cd67df-cbc3-45e0-9d64-99eb558416ad/configuration-system-failed-to-initialize-in-console-application-c?forum=csharpgeneral
I think, at this point, since I can’t read values at run-time from app.config – and I am out of time and need to move on – that I’ll add them as global variables, however hokey that is, directly in the class.
- Basic walkthrough if you don’t know how to open up a connection string in a c# console.
- This article on variables in debug within VS.