So, I have this fatal weakness for data warehousing. OLAP is way cool! That being said, I HATE spending time in reporting tools. Excel is great… like 15 years ago. I want to drop tables out there in the DW, and hand it off for others to do the less-glamorous (and never-ending) work of report-writing and analysis. Every developer has to constantly fight against being pigeonholed as a “report developer” – to the point where in the past I’ve avoided putting SSRS on my resume. It’s just to easy to get sucked into that world – there’s always a need for report analysts, and it’s just not as creative as the application/database design work we love. Get in and get out, that’s my motto!
So, PowerPivot is super cool. This is a free add-in to Microsoft Excel, and it couldn’t be easier. Once data is delivered I can unleash my users on our unsuspecting data – it’s truly self-service – and work on bringing more data into my warehouse for them as requests spiral, giving me more power and money! Bwah-hahahaha!
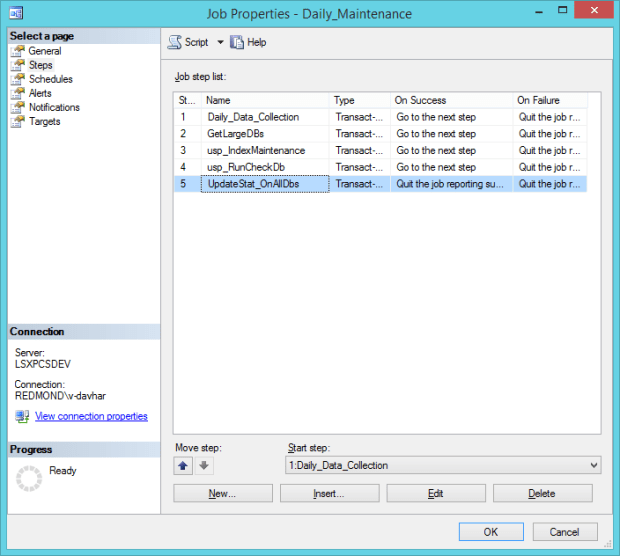
I started with a handy dandy star schema – with a central fact table and a couple tables off of this. Here’s a nice script for creating a date dimension:dim date

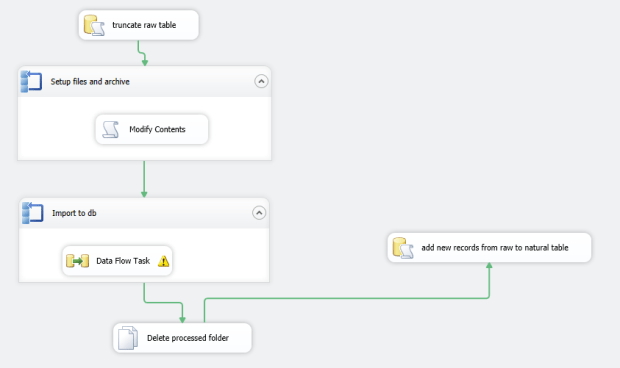
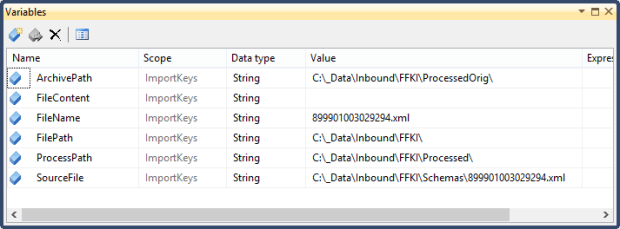
From this, I generate a table every day that’s optimized for Excel to pull from. By this I mean, it’s one table, very heavily indexed. (I played around with having one Excel spreadsheet hold Purchase Orders, Work Orders, and this central table – and was treated to a ton of ‘exceeded connection’ errors and bad performance. Bad Dave for being greedy! So, this ended up being three spreadsheets.)
I go into Excel and click on the PowerPivot menu item, and select Manage.
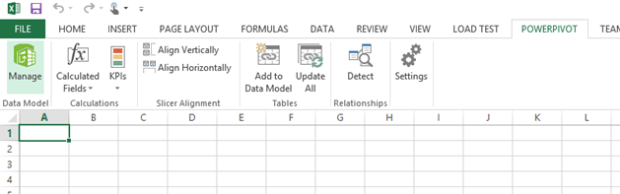
From here I select the From Database option and enter my connection info to my SQL Server box, and select my target table. Now I’m staring at this window:

This is our chance to hide or format contents. Here I right click on ItemProjectedID and hide that – it’s an identity field that the users we’ll never need – and if I wanted to I could change the format of the Supply/Demand/CumulativeBalance to Decimal.
It’s also worth noting that there’s a schema view. Here’s where I could add a hierarchy or a calculated field to dimension tables (like that Date dimension).
When I’m good and ready and the data table looks good, I select the PivotTable button. I could insert a split window with a chart at the bottom – but since our users just want a simple chart in this case, I’ll pick PivotTable.

Hmm. Now I’m seeing the below.
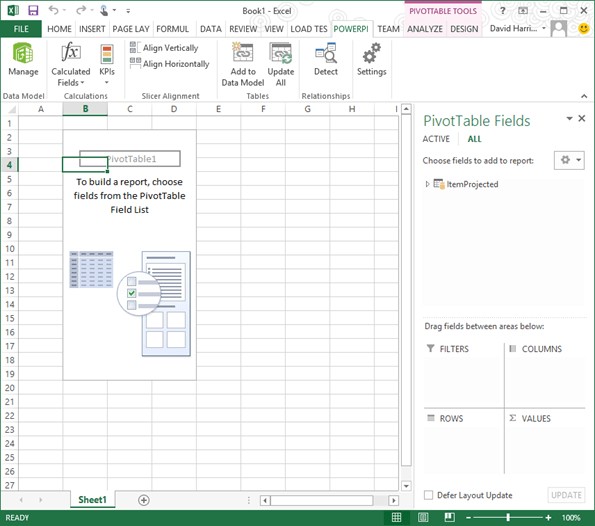
Let’s go crazy. Expand your data table – in my case I dragged on my Supply, Demand, and Cumulative number fields to the Values area on the lower right of the page. Then I dragged some of my descriptive rows (like ItemID, Date, and the RowDesc field) to the Rows area. Now I’m seeing this:

Muck around with the format a little bit. I found that when new fields dropped into a table I’d have to reconnect as if it was a new table – which is such a pain it’s better to create a new spreadsheet. But charts and graphs are awesome using this tool – think dashboarding – and if you save your XLS sheet out to a SharePoint document library (assuming your SP admin allows the Excel plugin) it looks and acts like a fancy-dancy dashboard with slicers:
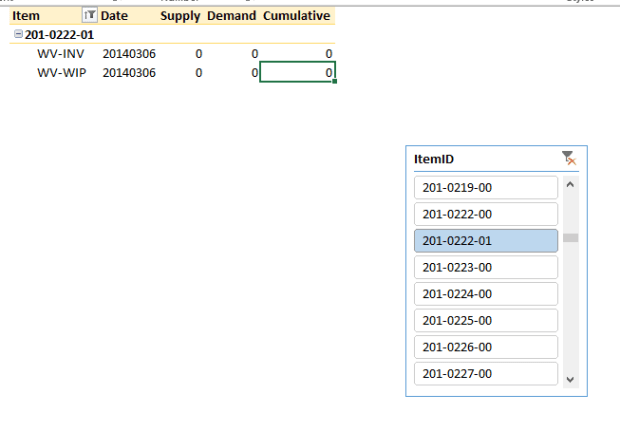
The best part is, I don’t need to muck around with writing reports. I gave my users a table – and exposed it to them using Excel, a tool they know and are familiar with. They can drag and drop values and play with it as they see fit. I guarantee you, your users will love you – and you’ll be able to get back to the “real” work of writing data flows and fancy-schmancy UI’s.
Data warehouse design notes
It bears repeating, but every company I’ve ever worked for ends up doing data warehousing wrong – the failure rate must be close to 90%! And it really comes down to two mistakes:
- Trying to solve every problem right out the gate.
- It’s a slippery road from star schema -> snowflake -> hellhole.
In short, if you try making it too big or too fancy, you’re screwed. How do you avoid this?
- Start with a simple date dimension and one very simple report use case.
- Use this to get your tooling straight, including your BI / self service report tools.
- THEN start growing out more dimensions and more fact tables. But beware! Have an architect around who’ll beat people over the head when they want to start chaining tables together (i.e. turning it back into a normalized system). It’s my personal belief that a set of data marts, each serving a specific purpose, are FAR more useful and easy to maintain than a Goliath system that pleases no one.
I’ve attached the SQL for building out a Date dimension – this is the one dimension that’s a constant in every DW I’ve worked with. It’s a great big flat table representing every date you’ll ever need – so the database won’t have to think when you want to slice data by quarter (for example) or to find the first day of the week of a year.
Helpful Videos and Links on PowerBI and PowerPivot
- http://www.youtube.com/watch?v=7W9DM2gE30U
- Dashboard in <20 minutes – kind of a soft annoying voice but the presentation is effective – http://www.youtube.com/watch?v=30I7d-cT1Tc
- A detailed walkthrough: http://office.microsoft.com/en-us/excel-help/tutorial-pivottable-data-analysis-using-a-data-model-in-excel-2013-HA102922619.aspx?CTT=5&origin=HA103240725